
生活中我们经常遇到意想不到的事情,在操作系统的世界里,也是司空见惯的,比如一段程序是将接收到的数据x代入公式y=10/x得到y,刚开始一切都很顺利,x=1,5,2…等等,都不会有任何问题,但输入0后,我们的程序就会出错。编过程序的朋友可能会说,那就在代码y=10/x之前做个判断就可以了,如果x等于0就不进行处理。这种异常的情况很容易得到解决,问题是从编码效率的角度来分析,代码在每次处理数据前都要进行判断,如果出错的情况有n种情况,就要判断n种情况,累积起来时延就会很长,那么我们怎么解决这个问题呢?简单办法就是每次得到数据不进行干预,按照正常的流程走就可以,当出现问题时,再对出错的情况进行判断,分别处理,有的情况是致命的错误,那么就退出程序,如果出现类似除0的错误,就跳过去,执行下一段代码即可,这样代码执行的效率就得到了很大的提高。以上的内容就是白话版的异常处理机制的目的,下面我们针对Windows实现,对异常机制进行描述。
编程人员眼中的异常处理下面的这段代码,编程人员都不会陌生,将有可能出错的部分框在try{}的括号里,当异常出现时,程序就跳转到__exception{}部分里的代码。
Voidtry_exception()
{
__try
{
*((int*)0)=0;
}
__except(ex_filter())
{
Global=1;
}
}以上代码是编程人员日常较多使用的,那么它的底层又是如何实现的呢?这就说来话长了,要从Windows的异常处理机制说起。
Windows编程中异常处理的一些概念
Windows中有一个中断向量表,包含256个条目,如图1所示。Windows将最底层的20个(0~19)保留给异常处理机制或者Intel保留,其中包括除0错误、调试、断点、溢出等情况。
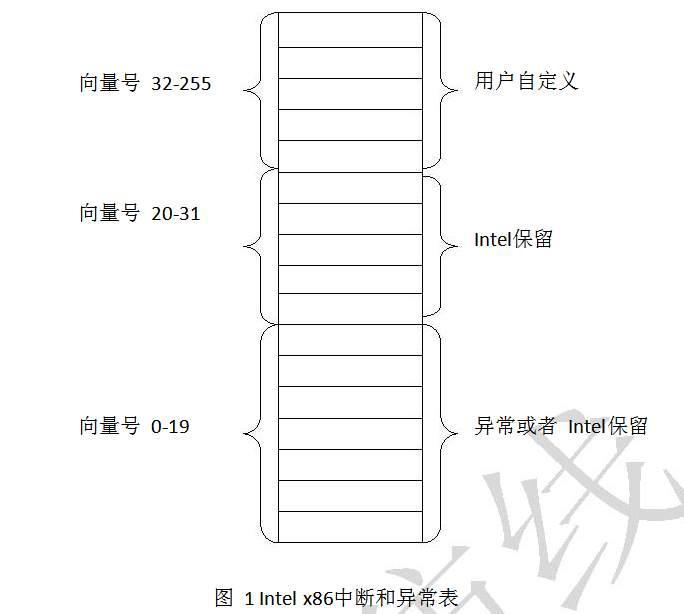
图1Intelx86中断和异常表
对于每个异常,不同的情况系统的处理并不相同。比如我们执行某段程序,而包含这段程序的页面未在内存中,遇到这种情况的异常,只要系统通过页面倒换程序将页面倒入内存后,出错位置的指令就可以得到运行,我们将这种异常叫做错误。在另外的情况下,比如我们在对程序进行调试时,遇到断点指令int3,则进入异常处理程序,当返回时,该条指令int3就可以跳过,执行下一条指令即可,这种异常可以叫做陷阱。还有一种情况无论是系统、调试器,还是应用系统都没招了,那么系统就不管了,索性让系统崩溃就可以了,这种异常就是崩溃了。具体的实现可以参看图2。
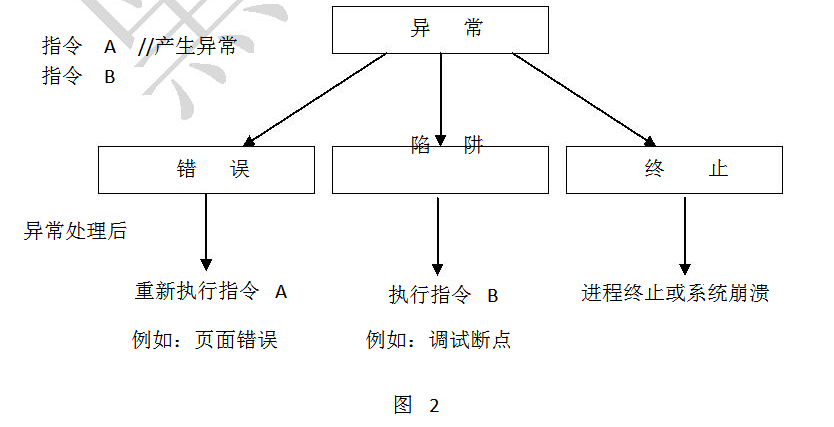
Windows中的异常处理
异常的处理实际上也可以认为是一个程序,那么相应的就会有一个处理流程。在Windows中,处理异常可以归结为:
①异常代码发生时,异常处理程序调用CommonDispatchException,在这个函数中,会构造2个对异常处理很重要的结构,_CONTEXT和_EXCEPTION_RECORD,这两个结构后面有详细描述。
②调用KiDispatchException函数,这个函数会根据发生异常时,是应用模式还是内核模式,分别对异常进行处理。
③异常处理完成后,调用_KiExceptionExit函数完成异常处理。我们可以将处理过程简单的归为异常处理前的准备工作①,异常处理的过程②和异常的退出③,下面我们也分为三部分对异常的处理进行讲解。
1)异常处理前的准备工作
异常处理前的准备工作可以分为两个阶段:异常发生前和异常发生后。我们先来看看前者。
异常发生前:
在这个步骤里,一个很重要的概念横空出世:结构化异常处理(StructuredExceptionHandler,SEH)。
很容易理解,在每次异常发生前,我们会根据用户或者系统编制的程序,将Try结构对应的部分作好处理,以准备当异常发生时,完成用户和系统交给的任务。每个异常的处理都要归为一个线程,我们查看每个线程的对应结构_NT_TIB,可以找到一些蛛丝马迹。
typedefstruct_NT_TIB
{
struct_EXCEPTION_REGISTRATION*ExceptionList;
//SEH链入口
PVOID
PVOID
PVOID
union{
StackBase;
//堆栈基址
//堆栈大小
StackLimit;
SubSystemTib;
PVOID
FiberData;
Version;
DWORD
};
PVOID
ArbitraryUserPointer;
struct_NT_TIB
}NT_TIB;
*Self;
//本NT_TIB结构自身的线性地址此处的_EXCEPTION_REGISTRATION结构很简单,就是一个指针和一个异常处理过程的地址:
typedefstruct_EXCEPTION_REGISTRATION
{
struct_EXCEPTION_REGISTRATION*Prev;
//前一个_EXCEPTION_REGISTRATION结构DWORDHandler;//异常处理过程地址
}每个线程的_EXCEPTION_REGISTRATION形成一个链表,如图3所示,其中链表头为Fs:[0],这是固定的,Fs是CPU的寄存器,Fs:[0]固定指向_NT_TIB的头部,实际上也就是指向_EXCEPTION_REGISTRATION的头。每次线程切换,Fs:[0]的内容都会相应的变化。
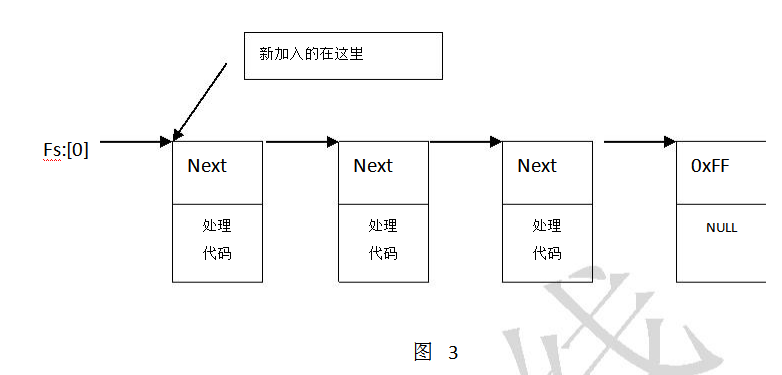
如果我们研究过异常处理的汇编代码,会经常看到如下熟悉的面孔:
Pushedx;
//存储异常处理代码的起始地址;
Pushdwordptrfs:[0]
//将当前的异常处理链表头压栈,堆栈中的内容为下一个异常处
理帧的地址;
Movdwordptrfs:[0],esp//使得fs:[0]指向当前的异常处理链表头,完成异常处理的插实际上,一段上面的代码序列就对应着一个应用程序中的一段Try结构,下面我们尝试入;着用通俗的语言来描述随着程序的执行,这个链表的变化。当编译程序(注意:是在编译部分)遇到一段Try结构时,就会在fs:[0]指向的链表中压入一个_EXCEPTION_REGISTRATION结构,实际上就是上面三句汇编代码。如果没有涉及到Try结构的嵌套,在代码的结束部分会将这个_EXCEPTION_REGISTRATION结构弹出,走过了一个鬼门关,注意这时异常链表又变成空的了,而如果涉及到Try结构的嵌套,那么嵌套了几级,异常链表中就会有几级,当异常发生时,从链表头开始查找处理例程,处理结束后,一个个退出,异常链表也会变空。另外可以注意到,在内层的try{}块最先得到处理,最外层的try{}最后得到处理,体现在链表中就是在内层的Try结构对应的_EXCEPTION_REGISTRATION加入到链表的前端。从图3也可以看出这种顺序。
我们以下面的例子说明异常发生前的工作与编程中的try结构的互相对应,假设一段程序的结构如下所示:
Try{
代码1
}
Exception{
Handler1;
}
Try{
代码2
Try{
}
代码3
Exception{
Handler2;
}
}
Exception{
Handler3;
}在上面这段代码里,代码1是相对独立的,代码2中嵌套了代码3,异常链表的长度则是0-1-0-1-2-1-0,变化的过程就不多说了,相信读者自会心领了。
异常发生后:
当异常发生时,操作系统会向引起异常的线程堆栈中填充_CONTEXT和_EXCEPTION_RECORD两个结构体的指针,分别指向_CONTEXT和_EXCEPTION_RECORD两个结构体,并且把这两个结构体的地址作参数传递给KiUserExceptionDispatcher,如图4所示。

CONTEXT结构体的任务,是保存异常线程的机器状态字,学过操作系统的人对这个结构不会感到陌生。实际上,这个结构记录的是异常发生时CPU的环境,如主要寄存器的状态等,如果这个异常被成功处理,要回到异常发生之前的环境,CONTEXT就可以帮助我们完成这个任务,从而让操作系统在异常产生的地方继续执行,当然,如果你要改变程序的流程,修改EIP的值就可以办到。以下是_CONTEXT结构的定义,可以看到正如我们所介绍的,是一些主要的寄存器,结构_CONTEXT包括:
typedefstruct_CONTEXT{
//CONTEXT标志
DWORDContextFlags;
//调试寄存器
DWORDDr0;
DWORDDr1;
DWORDDr2;
DWORDDr3;
DWORDDr6;
DWORDDr7;
//浮点寄存器
FLOATING_SAVE_AREAFloatSave;
//段寄存器
DWORDSegGs;
DWORDSegFs;
DWORDSegEs;
DWORDSegDs;
//通用寄存器
DWORDEdi;
DWORDEsi;
DWORDEbx;
DWORDEdx;
DWORDEcx;
DWORDEax;
DWORDEbp;
DWORDEip;
DWORDSegCs;
DWORDEFlags;
DWORDEsp;
DWORDSegSs;
//扩展寄存器
BYTE
ExtendedRegisters[MAXIMUM_SUPPORTED_EXTENSION];
}CONTEXT;描述异常的信息(也称异常记录)被保存在_EXCEPTION_RECORD的结构中,这个结构记录了异常码(案发原因)、异常标志(案发特征)以及发生异常的指令地址(案发地址)等,以便于应用程序或者内核根据这些信息对异常进行处理。
typedefstruct_EXCEPTION_RECORD{
DWORDExceptionCode;
DWORDExceptionFlags;
//异常代码,用于确定异常的类型
//异常标志,标示异常事件是否是连续的
struct_EXCEPTION_RECORD*ExceptionRecord;指向另一个异常纪录的指针。如果异常嵌套着产生,那么将产生一个异常链接表,如前述。
PVOIDExceptionAddress;
//异常发生的地址
DWORDNumberParameters;
DWORDExceptionInformation[EXCEPTION_MAXIMUM_PARAMETERS];//一个用于提供异常附加信息的32位参数的数组。
}EXCEPTION_RECORD;简而言之,_CONTEXT和_EXCEPTION_RECORD各有其功能,前者是为了穿越回发生异常时的环境,而后者是为了处理异常使用的。由于将与机器相关的环境记录和与机器无关的异常信息分开存储,使得异常处理机制能够在不同的平台上移植。
2)异常处理的过程
程序走到这里,我们为了应付这个异常的准备工作都已经准备完毕,主角也该登场了。
函数KiDispatchException()是异常处理的主要函数,接收到的参数如下:Exceptionrecord与_TrapFrame是我们前面提到的异常记录和异常环境,而PreviousMode表示的是发生异常时,程序是处于用户模式还是内核模式,须分别处理,参数FirstChance则说明的是第几次进入该函数,下面我们会讲到,处理的内容也不相同。
VOIDKiDispatchException( INPEXCEPTION_RECORDExceptionrecord, INPKEXCEPTION_ExceptionFrame, INPKTRAP_FRAMETrapFrame, INKPROCESSOR_MODEPreviousMode, INBOOLEANFirstchance );
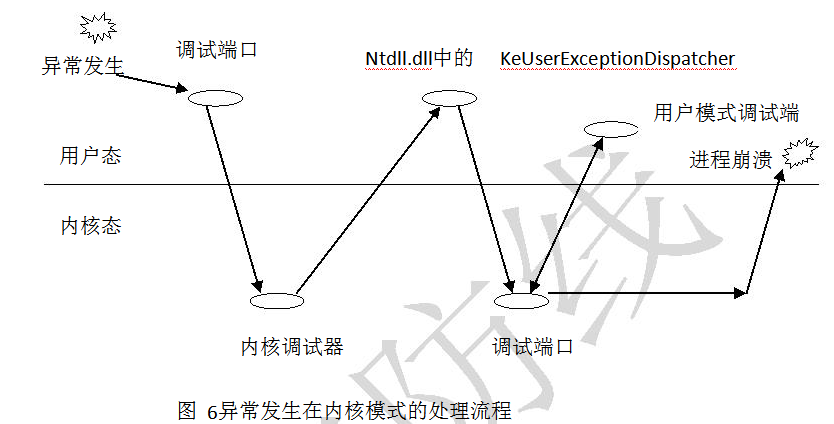
Windows对异常发生在用户模式还是内核模式的处理是不同的,我们分开描述,会使脉络更清楚一些。
内核模式
当一个异常产生在内核模式代码中时,此时的参数Firstchance为1,系统将异常交给内核调试器去处理,如果内核调试器不存在或者不处理,那么操作系统就查找内核堆栈结构,试图定位一个异常处理程序。如果异常处理程序没有被定位或是没有异常处理程序处理这个异常,那么设置参数Firstchance为0,再次将这个异常提交给内核调试器,处理则好,如果这次也不能处理,由于异常发生在内核模式,那么Windows就会退出崩溃。至于为什么会有调试器的出现,也很简单,这是操作系统制定的规则,以利于程序的调试。
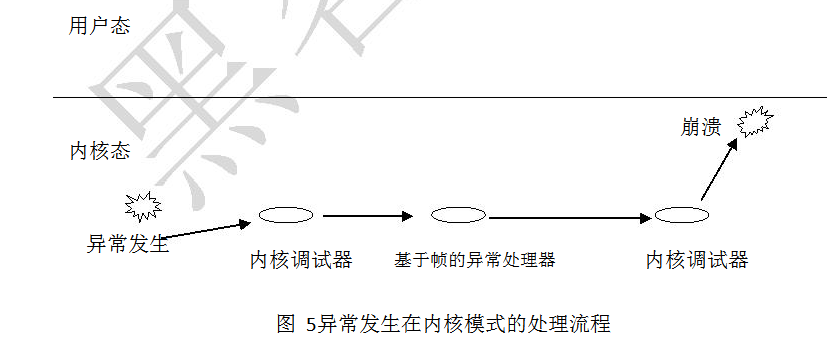
图5异常发生在内核模式的处理流程
用户模式
用户模式下的异常处理要较内核模式复杂,当用户模式的代码中有异常产生时,系统会用下面的搜索顺序来查找一个异常处理函数。
虽然异常发生在用户模式,但对异常的最初处理通常是在内核中,因此系统首先进入内核模式,查看是否有内核调试器可以处理这个异常。
如果进程没有被调试,或者有调试器而没有处理,系统就返回用户模式,此时会调用Ntdll.dll中的KeUserExceptionDispatcher函数,搜索产生异常的线程堆栈结构以找到该线程登记的异常处理程序。
如果没有用户模式的异常处理程序,则继续返回内核模式,这次系统会使用进程间通信的方式与该进程用户空间的调试程序联系,将异常的处理交给用户空间的调试器。
如果进程没有被调试,或者是和它关联的调试器没有处理异常,操作系统就根据异常类型提供默认处理。对于大多数而言,很遗憾,不得不终止产生异常的进程。
处理过程的流程如图6所示。
3)异常的退出
KiDispatchException函数返回后,程序会跳转到_KiExceptionExit函数(位于traps.asm)中,这个函数是所有异常处理程序的总出口。依然类似于上面异常的处理,处理程序的退出也分为用户模式和内核模式两种情况:
用户模式:如果有用户模式APC,则在返回用户模式前,调用KiDeliverAPC,交付这些APC,然后恢复必要的寄存器。
内核模式:调整esp寄存器的值。
最后都通过IRET回到异常发生处。
小结
异常在操作系统中的使用非常广泛,其过程可以归结为在异常发生前做好埋伏,发生后保护现场,处理异常,退出异常处理程序后,恢复被中断程序的运行。上面的内容也是本人的一些浅显理解,不到之处请谅解。