
前几年一直在进行ActiveX漏洞挖掘的研究,却一直没有将相关漏洞挖掘的经验总结下来,通过最近几次的文章总结一下,把自己的经验与大家交流分享。
ActiveX漏洞挖掘领域有5款工具,分别为Dranzer、axfuzz、COMRaider、AxMan和COMbust,其中axfuzz是这些工具的鼻祖,很多工具的底层都直接使用或借鉴了axfuzz工具。axfuzz为创建Dranzer工具而提供了初始化模型。axfuzz同时使用axenum程序和axfuzz工具来对系统上的软件进行评估,其中axenum程序用于枚举系统上的COM对象。axfuzz本身设计比较简单,仅仅使用0和超长字符串“AAAA...”来对组件的属性和方法进行测试。
重要的是,axfuzz提供了两个非常好的基础软件“axenum程序和axfuzz工具”,这两款软件可以作为其他漏洞软件的底层接口。
AxMan是一个基于Web的ActiveX的fuzz引擎。AxMan的目标是通过浏览器发现COM对象中的漏洞。既然AxMan是基于Web的,那么浏览器的任何安全变化都将影响到fuzz进程的结果,这比起其他的基于COM的评估工具更具有贴近实战的效果。(这让我想起了在桌面上生成的一些莫名奇妙的文件,这些文件说明了组件具有本地写的权限漏洞,这正说明了具有贴近实战的能力,因为跨域访问和浏览器的关系非常密切。)
AxMan工具架构
AxMan的整体架构如图1所示,整个框架主要涉及4个文件,分别是index.html、fuzzer.html、fuzzer.js和axman.js。
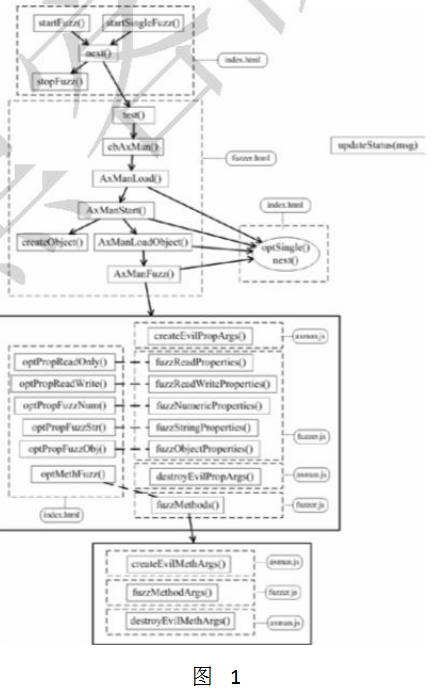
index.html文件
startFuzz()函数首先检查当前浏览器窗口是否支持ActiveXObject,然后对界面中的元素进行初始化。比如将stop按钮置灰为不可点击状态,将start按钮置亮,变为可点击状态,将startSingle按钮置为可点击状态,将report内容清空,然后执行next()函数。
startSingleFuzz()函数中,首先检查当前浏览器窗口是否支持ActiveXObject(window是JavaScript中最大的对象,它描述的是一个浏览器窗口),获取single按钮(即startSingle按钮)后面的clsid文本框中的值(该值是clsid号)。获取该字符串后,查看该字符串的第一个字符是不是“{”,如果不是则在刚才的clsid的前后附加“{”和“}”,这其实相当不完善,因为有可能出现这种情况,前面没有加“}”,但是后面加了一个“}”。之后对整个ax_objects进行遍历,找出值等于clsid的ax_objects。如果找到,则将stop、start、startSingle键进行初始化,report变量进行初始化,再执行next()。
fuzzer.html文件
fuzzer.html和fuzzer.js主要用于实现挖掘的步骤和流程,如图2所示.
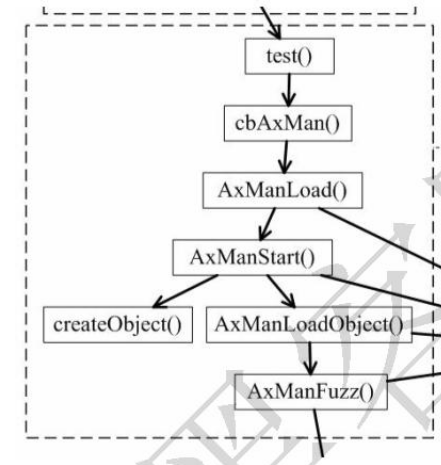
AxManLoadObject()函数很重要的一个作用就是obj=document.getElementById(target).object,该obj先传给fuzzMethods(obj),再传给fuzzMethodArgs(obj,f[Name],f[ArgCount],newArray())。该obj是什么,到底起什么作用呢?其实这里的target是类似于objectclassid=clsid:F43B35B7-C29A-453F-86E9-C37412269D62id=target//object中的target,我们平时在使用ActiveX时都要用到上面这句代码,并且一般情况下是利用target.xxx()的方式来调用某个函数。这里的document.getElementById(target).object应该类似于target.object,意思可能是获取该接口类对象。
AxManFuzz()函数通过createEvilPropArgs()生成恶意参数值,通过fuzzReadProperties(obj)试着访问所有属性,通过fuzzReadWriteProperties(obj)试着设置所有属性,通过fuzzNumericProperties(obj)试着设置所有的属性为数字,通过fuzzStringProperties(obj)试着设置所有的属性为字符串,通过fuzzObjectProperties(obj)试着设置所有的属性为对象,恶意属性参数已经用完,通过destroyEvilPropArgs()试着销毁所有的属性参数,通过fuzzMethods(obj)
对函数进行fuzz测试。
对于fuzzMethods(obj)函数,可以具体深入到每个{xxx}.js文件中看看,ax[clsid]其实是一个多维数组,代码如下:
ax[ax_name]=newArray(); ax[ax_name][Info]=DfrgCtlClass; ax[ax_name][ProgID]=DfrgCtl.DfrgCtl.1; ax[ax_name][Server]=C:\\WINDOWS\\system32\\dfrgui.dll; ax[ax_name][NotSafe]=true; ax[ax_name][FunctionCount]=24; ax[ax_name][Functions]=newArray();
ax[ax_name][FunctionCount]中存放的是接口中函数的个数。ax[ax_name][Functions]存放的是一个多维数组,该数组的每一维代表了一个函数,每一维又是一个数组。其功能描述如下:
因为ax[clsid][Functions]是多维数组,每一维代表了一个函数,那么“varfs=ax[clsid][Functions];”的意思就是取整个多维数组。
以函数的个数ax[ax_name][FunctionCount]为界,对ax[clsid][Functions]数组进行遍历。
跳过所有的属性,属性不需要在这里测试。
跳过所有的badmethod。
初始化状态条用于进度显示,“window.status=clsid+Method(Init)+f[Name];”。
调用createEvilMethArgs(f[ArgCount]),其中f[ArgCount]代表了某个函数中参数的个数。
fuzzMethodArgs(obj,f[Name],f[ArgCount],newArray()); destroyEvilMethArgs();
createObject()函数形式如下:
functioncreateObject(){
varcls=clsid.substring(1,clsid.length-1);
document.getElementById(axcontainer).innerHTML=
+objectid=targetclassid=\CLSID:+cls+\+/object;
}其中clsid的值是类似于{0A2A6ED1-D3F1-4A81-853D-93EC830CE388}这种形式,因此cls的值是0A2A6ED1-D3F1-4A81-853D-93EC830CE388。并且还要知道,如果想利用网页对ActiveX进行测试,网页中的代码必须具有类似下面的形式:
objectclassid=clsid:F43B35B7-C29A-453F-86E9-C37412269D62id=target//object因此会有语句+objectid=targetclassid=\CLSID:+cls+\+/object;我们最终可以发现,axcontainer元素中存放的页面语句包含了“+objectid=targetclassid=\CLSID:+cls+\+/object;”。
fuzzer.js文件
在fuzzMethods(obj)函数内调用了fuzzMethodArgs函数。fuzzMethodArgs函数调用时传入的参数为fuzzMethodArgs(obj,f[Name],f[ArgCount],newArray())。
函数fuzzMethodArgs(obj,meth,argc,argv)的整体框架如下:
//partI:Argumentsareset,makethecall
{
//Writethistothestatusbar
//Executethemethod
}
//partII:Simpletestformany-argumentmethods,
//实现MethArgsFast情况下的参数的组合
{
//Numerictesting
//Stringtesting
//Objecttesting
}
//partIII:Slowmodetesting-allpermutationsofargs,
//实现MethArgsSlow情况下的参数组合
//Copycurrentargs
//Whatindexdoesthislevelset?
//Numerictesting
//Stringtesting
//Objecttesting从上面的fuzzMethodArgs函数的框架可以看出,fuzzMethodArgs函数要处理整个fuzz过程,这个过程虽然不包括生成畸形参数,但是需要将畸形参数进行排列组合并传入到被测函数中。在函数fuzzMethodArgs开始执行的时候,argv参数是空的,也不能完全说是空的,其实传入的参数是newArray(),该数组没有任何数据。因为该函数调用函数时,为“fuzzMethodArgs(obj,f[Name],f[ArgCount],newArray());”最后传入的是空参数。函数开始运行的时候,不会先执行partI部分,而是根据情况先执行partII或partIII部分。partII或partIII部分的功能就是对参数进行排列组合,经过几轮后,参数组合排列出来,再使用partI部分对函数进行测试。
大体思路是这样的,当函数有1个参数或4个以上参数时,三种畸形数据(数字、字符串或对象)每次仅使用一种,对于一个参数好说,对于4个参数的函数时,就是以这一种畸形数据分别对函数的4个参数来测试,所有这些参数都是一个畸形数据。比如说上面的partII部分,代码如下:
//Numerictesting
for(vareidxinevilMethNum){
varargx=newArray();
for(varx=0;xargc;x++)
argx[x]=newArray(tNum,eidx);
fuzzMethodArgs(obj,meth,0,argx);
}先取一个畸形数字类型,然后构造函数的n个参数(n=4),每个参数都设定为当前取的这个畸形数字类型。在这里代入每个参数的其实是一个只有两个元素的数组newArray(tNum,eidx),前一个元素说明是一个数字类型,为了说明后一个元素的类型,后一个元素是具体的畸形数据。可见上面的argx并非函数最终使用的参数,因为参数不可能为数组,因此还要经过partI的转换。
最后的partIII最终带入的函数是“fuzzMethodArgs(obj,meth,0,argx);”,我们可能会由此想到函数是要进入partII,其实不然,因为if(argv.length==0&&(argcevilMethSlowMax||argcevilMethSlowMin))中,argv.length不等于0,所以进入的是partI。
partIII部分的实现思路是这样的:
在fuzzMethodArgs(obj,meth,argc,argv)函数中,先生成一个argx数组,对argv进行遍历,将argv中的值全部传给argx;计算argx数组的长度赋值给argi;eidx为畸形数据,将元素newArray(tNum,eidx)赋值给argx数组的最后一个元素argx[argi];递归执行“fuzzMethodArgs(obj,meth,argc-1,argx);”,其中带入argc-1比较反常。
如果是importCert(a,b,c)函数,则按以下步骤执行。
1)fuzzMethodArgs(obj,f[Name],f[ArgCount],newArray());即:fuzzMethodArgs(obj,importCert,3,newArray())
2)fuzzMethodArgs(obj,importCert,2,newArray((0,0)));其中(0,0)为一个元素。
3)fuzzMethodArgs(obj,importCert,1,newArray((0,0),(0,1)));
4)fuzzMethodArgs(obj,importCert,0,newArray((0,0),(0,1),(0,2)));
当fuzzMethodArgs函数的第3个参数为0时,就进入partI部分执行。
mcall=obj.importCert(targv[0],targv[1],targv[2])
info=obj.importCert(evilMethNum[0](xxxx),evilMethNum[0](xxxx),evilMethNum[1](xxxx))
axman.js文件
axman.js主要用于构造畸形数据。
createEvilMethArgsSlow(argc)和createEvilMethArgsFast(argc)之间的区别是什么?如果参数个数为2或3,那么程序的参数采用createEvilMethArgsSlow(argc)构造方式。
如果参数个数是1或者是4个以上(包括4个),则采用createEvilMethArgsFast(argc)构造方式。函数参数的复杂度取决于两个要素,一是单类型参数的复杂度,二是多个参数排列组合的复杂度。如果参数个数是2个或者3个,那么为了体现排列组合方面的复杂度,将适度减少单个类型参数的构造复杂度。如果参数个数是1或者是4个以上(包括4个),那么为了不使参数过于复杂,将取消排列组合方面的复杂度,但不会减少单个类型参数的构造复杂度。从参数类型的构造可以看出来,参数的构造尽量述求的是参数之间复杂的联系,在参数个数过多的情况下,将不再考虑参数之间的联系。
与之相对的另一种思路是:随着参数从少到多,单个参数的构造复杂度将减小,参数之
间的组合复杂度也随之减小。但是这种思路过于平均主义,不能抓住事物的本质,不是一个好方法。
对于createEvilMethArgsSlow(argc)来说,当参数只有1个的时候不用说,就是用3种类型的参数轮换着去试,分别以数字、字符串和对象去试,当有4个或4个以上参数时,就是分别拿3种类型的参数分别在4个参数上去试,剩下的参数给一个正常值。由于在构造单一参数上,createEvilMethArgsSlow(argc)仅仅是createEvilMethArgsFast(argc)的一个子集,所以下面将重点阐述createEvilMethArgsFast(argc)的构造方法。
从这里也能够说明架构设计时,安全性上的考虑。为了提高模块的安全性,应尽量减少函数接口的参数个数,在函数之间关系的复杂性和函数内部复杂性之间做一个很好的取舍和分割,这样才能最大限度的保证软件的安全。
总结
应该说整个软件工具的编程思想并不复杂,没有什么太多实质性的东西,唯一难度稍大的是对于多参数函数漏洞挖掘的处理,由于多个参数进行漏洞挖掘时要进行排列组合,会导致测试样本成指数级增长,因此作者对于多参数函数下的挖掘工作进行了简化。个人的观点是,可以先借助动态污染的思想找出多个参数之间的相关性,只有相关性达到或超过制定的阈值,所涉及的参数才进行排列组合,这样才能更充分的测试。第二点是函数之间的相关性,测试过程中发现两个函数A和B,如果先测试A函数再测试B函数,那么B函数将溢出报错,如果先测试B函数,将没有错误产生,经过事后验证发现两个函数存在相关性,A函数内的部分数据会被B函数使用,这样会造成某些隐藏漏洞的出现。除此之外,软件的很多方面还是很值得我们参考和学习的。