
随着信息技术的不断发展,计算机在社会和生活中扮演着日益重要的角色。越来越多的企业、商家、政府机关和个人将自己最重要的信息以数据文件的形式保存在计算机中。一旦电脑或者软件系统不可避免地出现差错从而导致数据丢失,如何能够迅速而正确地恢复就成为了至关重要的问题,这就使得数据恢复技术不论对个人、企业还是国家都显得日益重要。
FAT32已删除文件树构建算法
FAT32文件系统对数据区存储空间按簇进行划分和管理。簇是空间分配和回收的基本单位,即一个文件总是占用若干个整簇,文件所使用最后一簇的剩余空间就不再使用。簇的大小对文件系统的性能影响很大,当簇较大时,磁盘空间浪费往往较大,但存取效率往往较高;当簇较小时,磁盘空间可以得到有效利用,但存取效率往往很低。一般来说,一个簇往往取2的整数幂的扇区大小,大分区一个簇分配的扇区数往往要比小分区多。实际应用中,簇所占的扇区数大小存放在分区的BPB表中。
FAT文件系统为了实现目录间的双向联系,使系统能在目录之间进行有效切换,在每个子目录中都添加了“.”及“..”目录。其中“.”代表当前目录自身,“..”代表当前目录的父目录,指向父目录的起始簇号。故只要是目录文件,其最前面两个32字节在偏移00H处的值必然是0x202E及0x2E2E。而且,目录及文件的首个扇区的前32字节偏移1AH、1BH处的两字节内容存放了它们的首簇号低16位。所以,当假定一个首簇号后,即可定位到指定的目录区位置,直接读取目录区位置,判断前两个32字节中的偏移00H处的值,若满足0x202E、0x2E2E及其偏移1AH处的两字节为首簇号低16位,则可能是需要寻找的首簇号,若不然,则一定不是当前寻找的首簇号。
经过大量地实验分析,发现此方法让首簇号匹配成功的概率极大,因为首簇号高16位的值一般不会很大,即用户一般不会定义一个极大的逻辑分区。一个200G的分区,其循环次数也大概只有230次,故循环的次数必然很少。那么在循环次数很少的情况下,又能够准确的实现:首簇号低16位相同的情况下,假定一个首簇号高16位,组合成一个完整的首簇号,映射的数据区整好是一个目录区,这种匹配不成功的概率值太小。但反过来,若高16位相同,去匹配低16位,发现目录区而它又不是需要寻找的首簇号,这种概率可能会高出许多。这主要是因为其循环匹配的次数太多,值可以从0直到0xFFFF,共循环65535次。
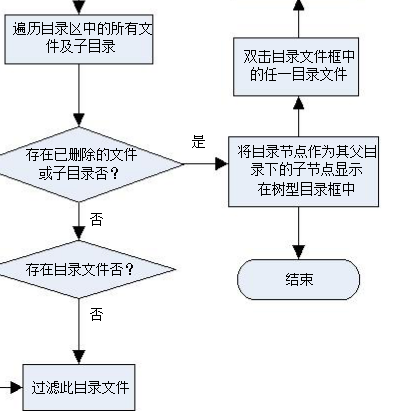
文件被删除时,不管其父目录、祖父目录等上层目录是否删除,在算法设计中,都需要将它们作为一个新的节点插入到重构的目录树中。因此,从根目录区开始遍历,只要发现目录文件,则获取文件的首簇号、文件目录名、MAC时间等各种属性值,并将其作为一个新节点插入到已删除文件及目录的临时目录树中。遍历完某个目录区中的所有文件及目录后,再对临时目录树中的目录节点进行判断,将目录文件的首簇号映射到其对应的目录区,依次遍历此目录区中的所有文件及子目录,判断是否存在删除文件及目录,一旦发现,则立即返回TRUE,否则深层次递归,直到遍历完所有的深层次子目录及文件。
因为FAT文件系统是一个倒型树结构,故程序设计时,为了缩短目录树构建的时间开销,可以每次只构建某一目录层次下的所有子目录及文件,在取证人员需要查看目录树中某一特定目录时,通过点击此目录再显示其目录下的文件及子目录。针对目录及其下的子目录及文件均被删除的情况,本文不再详细论述,因为只要是目录被删除,不管其子目录或文件是否删除,该目录节点肯定出现在已删除文件及目录的重构树中。任一FAT结构的逻辑分区中已删除文件及目录树的重构算法如图1所示。通过图中给出的目录树重构算法,可以完整的构建出FAT结构下的所有已删除文件目录树。
NTFS文件系统的一大特点是所有的数据,包括系统信息,如引导程序、记录整个卷的分配状态位图等都以文件的形式存在。MFT是NTFS卷结构的核心,系统通过MFT来确定文件在磁盘上的位置以及文件的所有属性。NTFS的结构原理这里就不再赘述了,读者可参考戴士剑老师编写的《数据恢复技术》第2版。
通过遍历NTFS卷下所有的MFT表项,就可很清楚地判断文件是否删除及文件名、文件数据起始簇号、簇数等等。那么如何将已删除文件及目录组合起来呢?笔者采用的是从目录树的底部开始逐渐往上构建整个目录树。算法基本流程如下:
(1)读取$MFT表项中80属性下的簇运行列表,获取每个簇运行结构的起始簇号与簇数,再根据首簇号和簇数,循环遍历NTFS卷下每个簇运行结构中所有的MFT表项。
(2)读取MFT表头,判断文件及目录是否删除,若目录及文件未删除,则直接忽略此MFT表项,转下一个表项;不然,则new一个新节点结构,获取表项中30属性下的文件名或目录名及父目录的MFT参考号。
(3)若父目录的MFT参考号不是0x05(即根目录下的文件或子目录),则转步骤(4);然后再判断此MFT对应的是文件还是目录,若为非目录文件,则读取80属性值,获取文件数据或文件数据的首簇号及簇数,存储到新节点结构体中,然后将此节点插入到目录树中;若为目录文件,则直接将此节点插入到目录树中。
(4)根据父目录的MFT参考号,读取每个父目录的MFT参考号,获取目录的文件名然后再调用搜索函数,在已部分构建的目录树中寻找此文件是否在目录树中,若没有搜索到,则new一个新节点,并将文件的文件名、文件及父目录的MFT参考号分别保存在该节点中,再判断此目录是否为根目录,若非,则保存此节点到目录树结构体的Vector数组中后递归调用,转步骤(4)继续读取其父目录的MFT号,若为根目录,则将此节点插入到目录树合适节点下;若搜索到了,则直接返回。
这样,即可全部获取NTFS卷分区中所有的已删除文件及目录,并构建好整个目录树结构。
下面给出具体如何将节点插入到目录树中,笔者设计了一种规则二叉树构建算法,具体如图2所示。
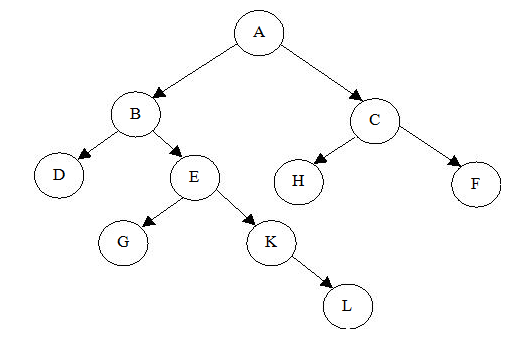
图2中给出的规则树定义如下:
(1)树中各节点代表目录或已删除文件,且节点的左子节点称为该节点的孩子结点,位于该节点的下一级目录。右节点则与该节点位于同一级目录。
(2)头节点A不代表任何含义,只为目录树的头节点,且节点C、F均为根目录下节点。
(3)若E节点为非目录文件,则K及其各右节点均为非目录节点,即位于同一层的节点,目录节点总是在非目录节点的前面,每次目录节点采用头插法,而文件节点采用尾插法。
上述规则树的定义,很好地将目录及子目录、子文件进行了梯次划分,那么假设上面的构建原理成立,排除图2中的正常目录节点(目录下的所有文件及深层子目录下的文件都不存在删除情况)呢?
排除正常目录节点。从根结点开始,遍历右节点,直到某节点不再是目录节点为止。依次对目录节点进行判断,若目录节点下存在文件节点,则跳过此节点;若此目录节点下不存在左孩子节点,则删除此目录节点,并将目录的右孩子节点直接指向它的父节点;若存在目录节点,则深层次递归判断是否存在文件节点,若不存在,则直接将此目录及其目录下的所有节点全部裁剪。通过上面的方式,如构建目录树的原理可行,则完全借助程序方式编码实现NTFS卷分区下的已删除文件的目录树重构。
数据恢复实践
在非常驻80属性下,记录了文件数据的数据运行列表,通过数据运行列表可以看出文件是否连续存储。如果数据运行结构有且仅有一个,则文件在磁盘上连续存储;反之,若运行结构不止一个,则断定文件在磁盘上离散存储。需要注意的是,数据运行列表中,每个运行结构中表示的首簇号总是前一个首簇号的相对偏移,且必须满足:当首簇号占一个字节时,其值不超过0x80,否则需要取负值。
如何将已经构建好的层次目录树能更好地在软件框架中显示(即先显示根目录,然后再依次显示其下的深层次子目录及文件),本文采用了先遍历头结点,再遍历右节点,最后遍历左节点的方法对二叉树进行完整遍历,然后将节点分为目录节点及非目录节点分别显示在软件框架的左右两侧,其中右侧的文件,在显示之前笔者通过动态数组对文件数据的首簇号及簇数事先保存下来,以便取证分析员有效地进行数据恢复。
当取证分析员或普通用户需要借助本软件进行数据恢复时,只需要选择已删除文件,然后点击恢复即可,软件会直接读取该节点下的数据信息或者首簇号及簇数,最后通过ReadFile函数将文件从对应的物理扇区中读取,并写入新建的磁盘文件中,完成数据恢复。
小结
本文主要对已删除文件目录树的重构进行了详细分析,并结合目录树的构建以及文件系统结构简要分析了数据恢复方法。本文讲述的数据恢复主要基于文件未被删除的情况,对于已经被覆盖的数据、完全低格、全盘清零、强磁场破坏的硬盘,则需要更底层的物理恢复技术实现。